Warning: This code no longer works since there has been a change in Leetcode’s website from the time this post was written.
I am, by no means, a Fangsexual and I don’t enjoy solving problems on the LeetCode, so I decided to find a way to quickly download the top 15 most voted solutions for any problem.
I’ve been playing around with Puppeteer and it seemed like a good idea to use it for something like this. If you don’t know what Puppeteer is then it’s a way to run Chromium in headless mode. It’s quite useful for things like automation and performing UI testing.
Puppeteer is a Node library that provides a high-level API to control Chrome or Chromium over the DevTools Protocol . Puppeteer runs headless by default, but can be configured to run full (non-headless) Chrome or Chromium.
The LeetCode uses Javascript/GraphQL to load the content so it’s not possible to send a simple HTTP request and parse the HTML. This is where Puppeteer comes in handy. Puppeteer, being a headless browser, can execute Javascript, and we can use this fact to wait for websites to load content via Ajax calls.
const leetcodeDiscussionPage = "https://leetcode.com/problems/reverse-pair/discuss?currentPage=1&orderBy=most_votes";
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(leetcodeDiscussionPage);
await page.waitForSelector(".topic-item-wrap__2FSZ")The important line here is 'await page.waitForSelector(".topic-item-wrap2FSZ")'. This line is waiting for HTML element with the class name ‘’topic-item-wrap2FSZ" to show up since it’s this element that contains the title and the link for each solution.
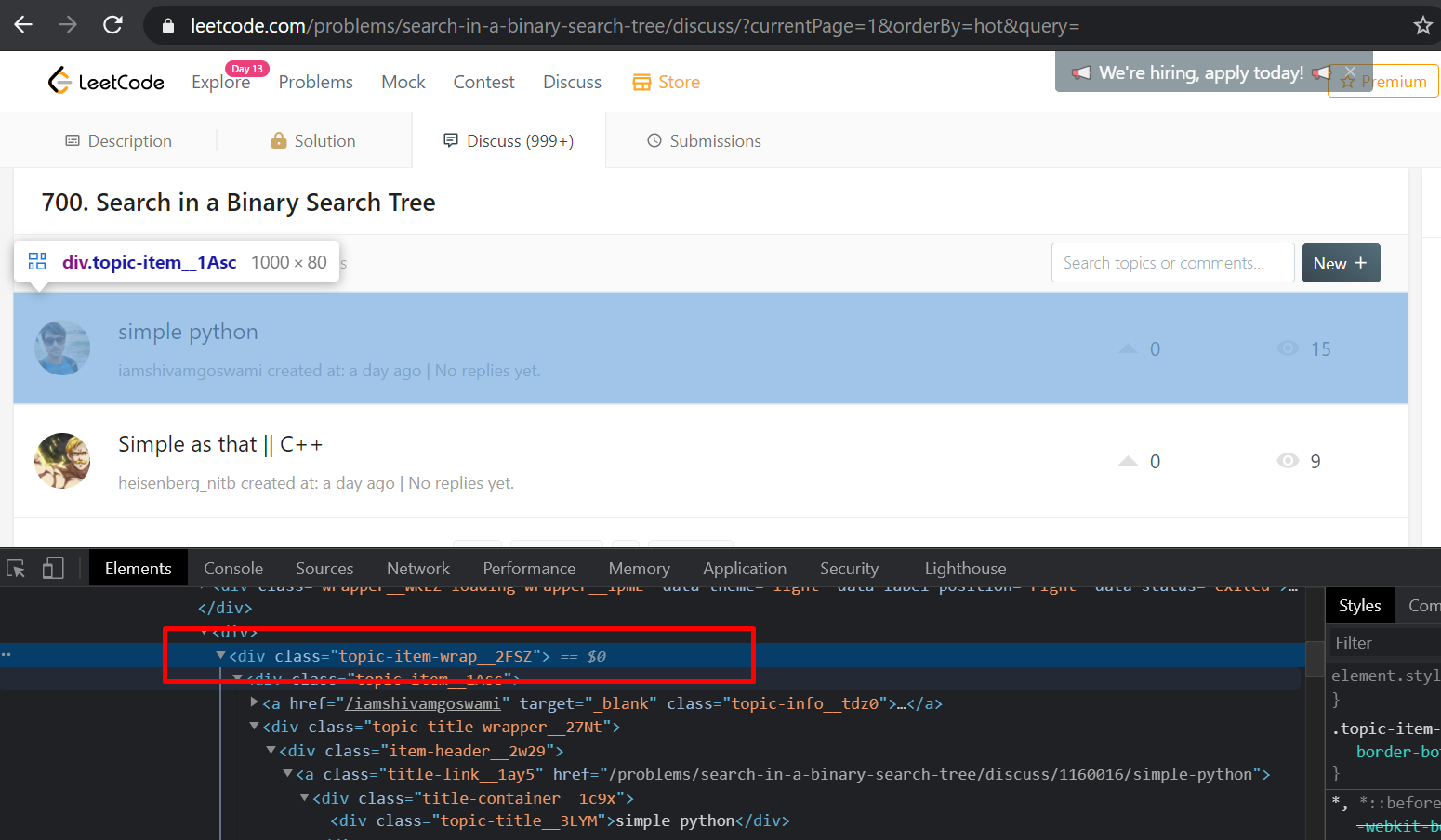
Once the discussion topics are loaded we can scrape for the title and the solution. To get all solutions we need to select all elements with the 'topic-item-wrap__2FSZ' class name and loop through them to extract the title and the link to the solution.
Puppeteer makes it simple enough to select the elements with the same class name.
const elements = await page.$$(".topic-item-wrap__2FSZ");
const solutions = await Promise.all(elements.map(async el => {
const solution = getSolutionDetails(el);
return solution;
}));
function getSolutionDetails(element) {
const title = await el.$eval(
".topic-title__3LYM",
el => el.textContent
);
const solutionLink = await el.$eval(
".title-link__1ay5",
el => `${origin}${el.getAttribute("href")}`
);
return { solutionLink, title };
}The important thing here is the usage of element.$eval. We use element.$eval and pass it two arguments:
-
a query selector string, which in our case is just the class name
.topic-title__3LYM -
a callback to handle the resulting element and manipulate or extract an attribute from it
In the first case, we extract the textContent property and in the second instance, we extract the href attribute.
Alright, so half of our job is done, we have the discussion title and the link to the corresponding discussion that contains the solution. So we just need to repeat the procedure for each discussion links and extract the corresponding solution.
If you go to any of the discussion pages and inspect element via dev tools, you’ll notice that all of the solution and corresponding solution shows up inside an element with discuss-markdown-container.
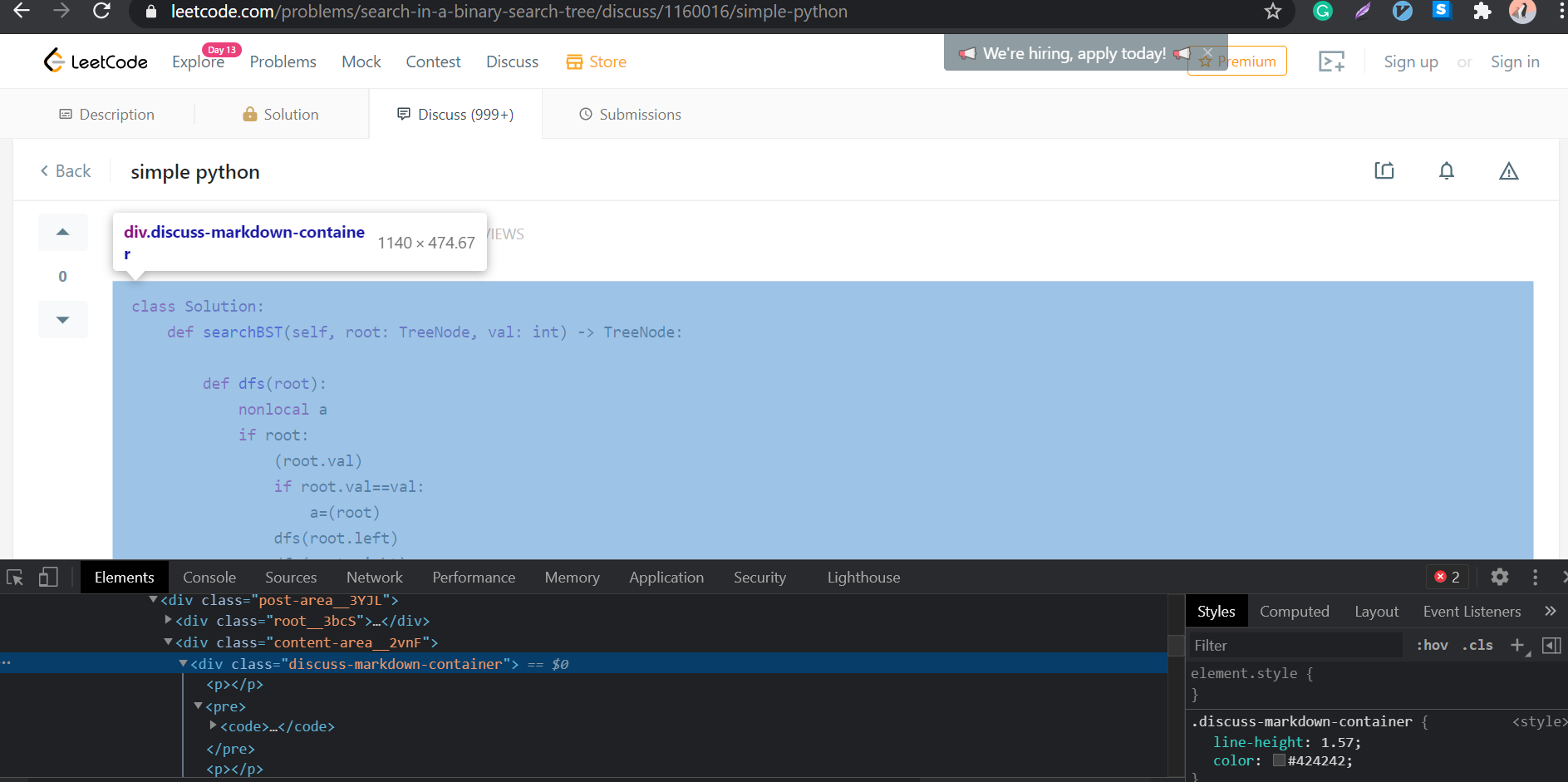
So by now, we know that we just have to wait for it to show up and extract the text content and we can modify our getSolutionDetails function to include a call to include the actual solution as well.
async function getSolutionDetails(element) {
const title = await el.$eval(
".topic-title__3LYM",
el => el.textContent
);
const solutionLink = await el.$eval(
".title-link__1ay5",
el => `${origin}${el.getAttribute("href")}`
);
const solution = getSolution(solutionLink)
return { solutionLink, title, solution };
}
async function getSolution(link) {
const page = await browser.getNewPage();
await page.goto(link);
await page.waitForSelector(".discuss-markdown-container");
const markdown = await page.$eval(
".discuss-markdown-container",
el => el.textContent
);
await page.close();
return markdown
}
The result can, of course, be saved to a text file or a markdown file. It can be a pain in the ass to pass around the browser and page instances in the code, so it’s just better to enclose wrap all of this in a class. This way you don’t have to keep browser instance in global scope or, worse, have multiple browser instances.
The whole code for this post can be found here